

Hey friend,
Last week, we talked about the progression of Language Models from inception to Transformers. We explored the various mechanisms and innovations that led to a truly pathbreaking technology in the form of Transformers. Today, we will take a journey in time and look at how we got from Transformers to the current state-of-the-art - MultiModal Large Language Models and why they are, truly, the pinnacle of human engineering, mathematics, and computing.
1. Foundational Concepts in Modern Language Models:
Before we delve into the exciting world of modern-day LLMs, there are a few concepts that I would like to introduce as these will - broadly - form the basis of understanding how these beautiful models work. Some of my more technical readers will already know what these terms mean. You guys can skip ahead to the story. For my non-technical readers, please stick with me!
When talking about any machine learning model - it is important to understand that the learning process is broadly divided into two broad parts - model training and model inference.
Model Training:
Let’s look at a few definitions of model training according to some of the most popular sources on this topic.
C3 AI: C3 AI is one of the biggest enterprise AI software companies. Their definition of training a model is as follows:
“Model training is the phase in the data science development lifecycle where practitioners try to fit the best combination of weights and bias to a machine learning algorithm to minimize a loss function over the prediction range. The purpose of model training is to build the best mathematical representation of the relationship between data features and a target label (in supervised learning) or among the features themselves (unsupervised learning). Loss functions are a critical aspect of model training since they define how to optimize the machine learning algorithms. Depending on the objective, type of data and algorithm, data science practitioner use different type of loss functions.”1
According to Amazon AWS, model training is defined as
“The process of training an ML model involves providing an ML algorithm (that is, the learning algorithm) with training data to learn from. The term ML model refers to the model artifact that is created by the training process."2
Databricks - which is a popular platform for learning about data science and machine learning defines model training as
“The process of running a machine learning algorithm on a dataset (called training data) and optimizing the algorithm to find certain patterns or outputs is called model training. The resulting function with rules and data structures is called the trained machine learning model."3
All these definitions are current and give us some very important information about training a model. The common theme between all three of them is feeding the model with a lot of data to train on or to build a mathematical representation of the patterns in the data it is fed. However, on a more abstract level of understanding, it is one of the most fundamental processes in the world - learning. All it comes down to is learning how to perform a certain task given a set of data. Looking at it in this context, pattern recognition, fitting a curve, and building a mathematical representation of the data - all start to make a lot more sense. This is the process of teaching. Except here, we are doing it with a machine. The process looks very similar to the process of learning for humans. You show a person (or a model) enough examples of something and they will learn to recognise it.
In the context of Machine Learning, training involves a couple of important factors - any model will learn how to perform a task, but it will need to be exposed to a large amount of data. During training, the model adjusts its internal parameters (weights) to minimise the difference between its predictions and the actual outcomes in the training data.
For language models, the scale of this process is staggering. Models like GPT-3 are trained on datasets ranging from 570GB to 45TB of text – an amount of information that would take a human multiple lifetimes to consume.4
However, as language models have grown more sophisticated, researchers have recognized that training models for specific tasks may not be the most efficient approach. What if we could create a model with a broad understanding of language, which could then be adapted to various specific tasks?
This question leads us to an important evolution in the training process: pre-training. In pre-training, instead of training a model for a specific task, we train it on a vast and diverse corpus of text to develop a general understanding of language. This pre-trained model can then serve as a starting point for more specialized applications.
Pretraining: Building a Foundation of Knowledge
Pretraining is like giving a student a broad education before they specialize in a particular field. Instead of training a model for a specific task, we expose it to a vast and diverse corpus of text to develop a general understanding of language.
This approach allows the model to grasp the nuances of language structure, idioms, and even some aspects of world knowledge. It's akin to a student reading a wide variety of books across different subjects before choosing their major.
The beauty of pretraining lies in its versatility. A pre-trained model serves as a strong foundation, ready to be fine-tuned for specific applications. Which brings us to our next concept: fine-tuning.
Fine-tuning: Specializing for Specific Tasks
If pretraining is like a broad education, fine-tuning is akin to specializing in a particular field. In this process, we take our pre-trained model – with its broad understanding of language – and further train it on a smaller, task-specific dataset.
Fine-tuning allows the model to leverage its general language understanding while honing in on a particular application. It's like a medical student who, after years of general medical training, specializes in cardiology or neurosurgery.
By combining pretraining and fine-tuning, we get the best of both worlds: a model with a deep, general understanding of language that can also excel at specific tasks.
As we continue our journey through the evolution of language models, we'll see how these concepts – training, pretraining, and fine-tuning – have been applied and refined, leading to the remarkable capabilities of today's state-of-the-art models. From BERT to GPT, from task-specific models to multimodal marvels, each step forward has built upon these foundational concepts, pushing the boundaries of what's possible in natural language processing.
Now, we will dive deeper into some of the landmark models that have shaped the field, exploring their architectures, the algorithms and intuitions that form their bases, training approaches, and how they are used to understand the scale of the impact they have had on the world.
2. The Era of Pre-trained Models
The dawn of pre-trained models marked a revolutionary shift in the field of Natural Language Processing (NLP). This era, which began in the late 2010s, is characterized by models that leverage vast amounts of unlabeled text data to learn general language representations before being fine-tuned for specific tasks. Two model families stand out as the pillars of this new paradigm: BERT, which transformed our approach to understanding context, and the GPT series, which pushed the boundaries of generative capabilities and model scaling.
2.1 BERT and Bidirectional Context
BERT (Bidirectional Encoder Representations from Transformers), introduced by Google in 2018, fundamentally changed how we approach language understanding tasks. Its name aptly captures its key innovation: the ability to consider context from both directions when processing language.
Let’s dive deeper into this and understand what this means:
2.1.1 Core Idea: Bi-directional Context and Encoder-Only Architecture
BERT’s primary innovation, as we saw lies in its ability to consider context simultaneously from both directions when processing language. It achieves this by considering the context of a word by simultaneously looking at the words both before and after it in a sentence. This is in contrast to a more unidirectional approach of other models which only look at the context from one direction (left-to-right or right-to-left) when processing text. This bidirectional approach allows BERT to capture more nuanced and context-dependent meanings of words and phrases.
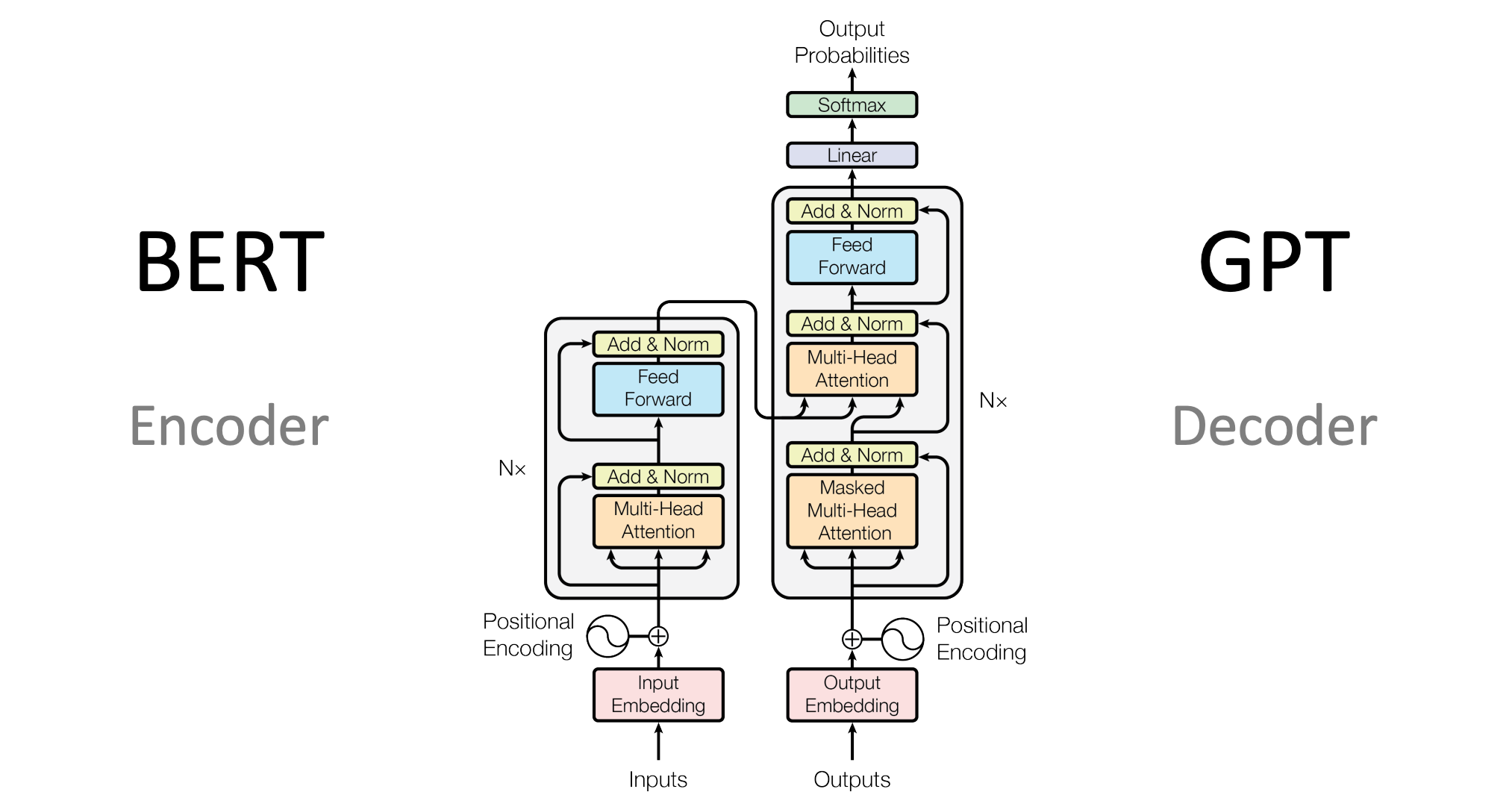
An important characteristic of BERT is that it is an encoder-only model, i.e., it utilizes only the encoder part of the original transformer architecture.56 As an encoder, BERT’s primary function is to process input text and create rich, contextual representations of that text. This has several key implications:
Bidirectional Context: As discussed earlier, BERT simultaneously considers the entire context, capturing the relationships between words regardless of their position in the input sequence.
Input Processing: BERT takes a sequence of tokens as input and produces a sequence of vectors, each representing the contextual embedding of the corresponding input token.
No Generation: Unlike decoder models like GPT (we will talk about this in the next section), BERT is optimized for understanding and representing text, not generating it.
Task Flexibility: The contextual representations produced by BERT can be used for various downstream tasks by adding task-specific layers on top of the pre-trained model.
2.1.2 Understanding the Architecture
BERT’s architecture is based on the encoder portion of the Transformer model. Let us dive deeper into how this works and what it means for the model.
Input representation: BERT uses WordPiece embeddings with a 30,000-token vocabulary.7 Here, each input token has three embeddings added together:
Token Embeddings: A learned embedding for each word piece token.
Segment Embeddings: A learned embedding for sequence A (E_A) or sentence B (E_B) to differentiate between sentences.
Positional Embeddings: A learned embedding for each position in the sequence to retain order information.
Mathematically we can express the input representation as follows:
\(E_{input} = E_{token} + E_{segment} + E_{position}\)where E represents the embedding.
Model Variants: BERT comes in two sizes - a base model (BERT Base) with 12 layers, 12 attention heads, and 110 million parameters and a large model (BERT Large) with 24 layers, 16 attention heads, and 340 million parameters.
Transformer Encoder Layers: Each layer consists of
Multi-head attention
Feed-Forward Neural Network
Layer Normalization and Residual Connections
Note: I briefly talked about attention mechanisms last week while discussing the Transformer. If you want, you can skip this section and move on to the rest of it for brevity’s sake.
However, this is a much more detailed discussion about how these various attention mechanisms work because I think these are very cool and fundamental to the understanding of modern attention-based language models.
2.1.3 Self-Attention Mechanism
At the heart of BERT’s architecture is the self-attention mechanism, which allows the model to weigh the importance of different words in the input when processing each word. The computation behind this self-attention mechanism is as follows:
Where Q, K, and V represent query, key, and value matrices respectively. and d_k represents the dimension of the key vectors. These are learned matrices that are derived from the input sentence/sequence. Let’s break them down further:
Q (Query): Represents the current token/word that the model is trying to focus on.
K (Key): Represents the elements the model is comparing the query against to decide how much focus should be given.
V (Value): Represents information that is passed along after attention scores/values are computed in the current computation step.
d_k: Represents the dimension of the key vectors. In this computation, division by the square root of this vector is useful in stabilizing gradients and avoiding very large values, which could make the activation function (softmax) push most of the attention weights towards very small values.
In this computation, the dot product of the matrix Q with the transpose matrix of K gives a matrix in which each entry corresponds to a similarity score between the query vector and key vector. The higher the dot product, the more similar the two vectors are.
Then, the dot product values in this new matrix are scaled by a factor of 1/sqrt(d_k) to prevent large dot product values from overwhelming the softmax activation function as discussed earlier. Without this scaling, the softmax function could cause the attention mechanism to become too sharp, decreasing the model’s effectiveness.
After scaling, the softmax activation function is applied. This normalizes the values into a probability distribution where each element indicates how much attention should be paid to different tokens in the input sequence.
Finally - the resulting attention weights are multiplied by the value vectors (V). This step applies the learned attention distribution to the values, effectively gathering information from different parts of the input, weighted by their relevance as determined by the attention mechanism.
This is also called scaled dot-product attention. The goal here is to determine how much focus or “attention” each word (token) in a sequence should give to every other word in the sequence. The intuition behind this is that the query seeks relevant information from all keys and the attention weights are used to retrieve the corresponding values. The scaled dot-product attention helps the model focus on the most relevant parts of the input and thus enhances its ability to capture relationships between different tokens/words in the sequence/sentence.
A good resource to understand how self-attention works better is the explanation by Prof. Tom Yeh in his blog “AI By Hand.”
2.1.4 Multi-Head Attention
BERT uses multi-head attention, which allows the model to jointly attend to information from different representation subspaces at different positions. Multihead attention is defined as:
where, once again, we see the same Query (Q), Key (K), and Value (V) matrices as we saw in self-attention. head_i is an individual attention head and W^O is the weight matrix used to transform the concatenated heads into the final output.
And each head (head_i) is computed as:
In multi-head attention, we apply the same concept of scaled dot-product attention mechanism as in self-attention, but now, each head has its own set of learned projection matrixes (the W_i matrices for Q, K, V) which are responsible for linearly transforming the original Q, K, V matrices into lower-dimensional subspaces. This allows each head to focus on different aspects of the input - making multi-head attention so powerful as each head can now specialize.
We then use these transformed Q, K, and V matrices to compute attention. Here, each attention head will produce a different output based on how it computes the attention over these transformed matrices.
Coming back to the multi-head mechanism, we concatenate the outputs from all attention heads along the feature dimension to form a single output matrix Concat(head_1,…,head_h). This concatenated output will have a shape that combines the dimensions of all the heads.
After the concatenation operation, we pass the results through a final linear transformation using the weight matrix W^O to combine the information from all heads into the desired output space.
Doing this gives us the ability to get multiple perspectives as each head focuses on a different part of the input sequence. For example: One head might focus on short-range dependencies while another head might focus on long-range dependencies - thus capturing different parts of the context.
This approach also gives us a lot of flexibility and the ability to parallelize as we can use multiple attention heads to simultaneously gather information from different parts of the input sequence and capture different kinds of relationships and patterns in the data in the process.
2.1.5 Pre-training Tasks
BERT is pre-trained using two key unsupervised tasks designed to encourage a deep understanding of language context:
Masked Language Model (MLM):
15% of the input tokens are randomly masked.
The model is trained to predict these masked tokens based on the surrounding context.
This forces the model to rely on bidirectional context, allowing it to understand how words relate to each other in both directions.
The MLM Objective function can be represented as\(L_\text{MLM} = -\mathbb{E}_{x \in X} \log P(x_\text{masked} | x_\text{unmasked})\)where X represents the input data and the model predicts the probability of the masked tokens given the unmasked one.
Next Sentence Prediction (NSP):
The model is presented with two sentences, and it must predict whether the second sentence (B) logically follows the first sentence (A) in the original text.
This task improves the model’s ability to understand relationships between sentences.
The objective function for NSP can be expressed as\(L_\text{NSP} = -\mathbb{E}_{(A,B) \in D} \log P(\text{IsNext}|A,B)\)where D is the set of sentence pairs in the training data. Combining these two gives us the total pre-training objective as the sum of NSP and MLM in the following manner:
\(L = L_\text{MLM} + L_\text{NSP}\)
2.1.6 Training Process
BERT’s training process is a two-stage process involving pre-training and fine-tuning:
Pre-training:
BERT is initially pre-trained on large corpora, including the BooksCorpus (800 million words) and English Wikipedia (2.5 billion words).
The Adam optimizer8 is used with parameters β1=0.9β1=0.9 and β2=0.999β2=0.999.
The learning rate follows a warmup schedule, gradually increasing over the first 10,000 steps to a peak of 1e-4, then decaying linearly.
Pre-training is conducted for 1 million steps with a batch size of 256 sequences.
Fine-tuning:
After pre-training, BERT is fine-tuned on specific downstream tasks (e.g., question answering, and sentiment analysis).
Fine-tuning typically requires only a few epochs on task-specific datasets, leveraging the pre-trained knowledge for specific tasks.
2.1.7 Computational Analysis
Training BERT at scale posed several computational challenges due to its sheer size and complexity:
Model Size:
BERT-Base: Consists of 110 million parameters.
BERT-Large: Grows significantly to 340 million parameters.
Training Data: BERT was pre-trained on a vast dataset comprising 3.3 billion words from the BooksCorpus and English Wikipedia.
Hardware Requirements: Pre-training BERT-Large demanded substantial computational power, utilizing 64 TPU chips for 4 days.
Optimization Techniques:
Adaptive learning rates through the Adam optimizer to handle the varying learning rates across layers.
Gradient clipping to mitigate exploding gradients and ensure stable training.
Warmup steps to gradually ramp up the learning rate, stabilizing the model during the early stages of training.
Memory Efficiency:
Gradient checkpointing was employed to reduce memory usage during backpropagation by storing intermediate results more efficiently.
Mixed precision training leveraged the capabilities of tensor cores in modern GPUs, optimizing the balance between speed and memory usage.
2.1.8 Impact and Performance
BERT achieved state-of-the-art results on eleven NLP tasks, including:
GLUE benchmark: 80.5% (7.7% point absolute improvement)
SQuAD v1.1 question answering: 93.2% F1 score
Named Entity Recognition on CoNLL-2003: 92.8% F1 score
These results demonstrated the power of large-scale pre-training and sparked a new era of transfer learning in NLP.
BERT was evaluated on a wide range of tasks, demonstrating its versatility:
GLUE Benchmark: Includes tasks like question-answering, sentiment analysis, and textual entailment.
SQuAD v1.1 and v2.0: For question-answering capabilities.
SWAG: For commonsense inference.
BERT's strong performance across these diverse tasks highlighted the power of its bidirectional approach and the effectiveness of its pre-training tasks.
2.1.9 BERT as a Foundation Model
BERT is considered a foundation model, a concept that has gained prominence in recent years. Foundation models represent a paradigm shift in artificial intelligence, particularly in the field of natural language processing.9 As a foundation model, BERT exhibits several key characteristics:
Pre-training on diverse, large-scale datasets: BERT is trained on vast amounts of unlabeled text data (BookCorpus and English Wikipedia), allowing it to capture a wide range of language patterns and knowledge.10
Self-supervised learning: BERT uses clever techniques (MLM and NSP) to create its own supervised tasks from unlabeled data.11
Generalized representations: The knowledge acquired during pre-training can be applied to a variety of downstream tasks through fine-tuning or feature-based approaches.12
Transformer architecture: BERT uses the Transformer architecture, which has become a standard in many foundation models.1314
The power of foundation models like BERT lies in their ability to learn general-purpose representations that can be adapted to a wide range of tasks with minimal task-specific training data. This has led to significant improvements across various NLP benchmarks and opened up new possibilities in language understanding.15

2.2 GPT: Generative Pre-Trained Transformer
2018 was something of an arms race year for foundational Language Models that would go on to change the world forever. This was kicked off by OpenAI introducing the Generative Pre-Trained Transformer (GPT) and was quickly followed by Google introducing BERT in October 2018. While BERT focused on bi-directional context for understanding tasks, GPT demonstrated the potential of large-scale unsupervised pre-training for generative language tasks.16
This was the model that went on to become the first in a series of increasingly powerful language models. It truly demonstrated the potential of large-scale unsupervised pre-training for language understanding tasks.
2.2.1 The Core Idea: Unsupervised Pre-training and Supervised Fine-tuning
GPT's innovation lies in its two-stage approach to natural language understanding:
Unsupervised Pre-training: The model is first trained on a large corpus of unlabeled text, learning to predict the next word in a sequence. Given a sequence of tokens - (u_1, u_2, u_3,…, u_n) the model is trained to maximise the following objective function:
\(L_1(U) = \sum_i log P(u_i|u_{i-k}, ..., u_{i-1}; \Theta)\)where k is the size of the context window and θ refers to the model parameters.
Supervised Fine-tuning: The pre-trained model is then fine-tuned on specific tasks with labelled data.
This approach is very analogous to how we humans learn language: we first gain a general understanding of language through exposure to vast amounts of text (like reading books), and then we learn to apply this knowledge to specific tasks (like answering questions or writing essays).
2.2.2 Understanding the GPT architecture:
GPT is based on the decoder portion of the Transformer architecture introduced by Vaswani et al in 2017. It is designed for generating text, and sequentially processing inputs from left-to-right. Let’s dive into how it works:
Input Embedding Layer: In this layer, words or input tokens are transformed into continuous vector representations, making them understandable to the model.
Positional Encoding: Since GPT sequentially processes inputs, positional encoding is important to retain information about the order of the words in sequence when feeding the input sequence to the model to better understand the structure of the input sequence.
Multiple Transformer Decoder Layers: GPT uses several layers that repeat the decoding steps of the Transformer architecture. This works in the following order:
Multi-head self-attention: This allows the model to pay attention to different parts of the input when processing each word, helping it capture relationships between words in a sentence.
Layer Normalization 1.0: This operation stabilizes the training process, helping the model learn more efficiently.
Feed-Forward Neural Network: After applying attention, each word is further processed through a small neural network to refine its representation.
Layer Normalization 2.0: This step is applied for additional stability
Output Layer: Finally, a linear layer followed by a softmax function is used to predict the next token/word in the sequence.
Figure 217 explains this architecture visually,
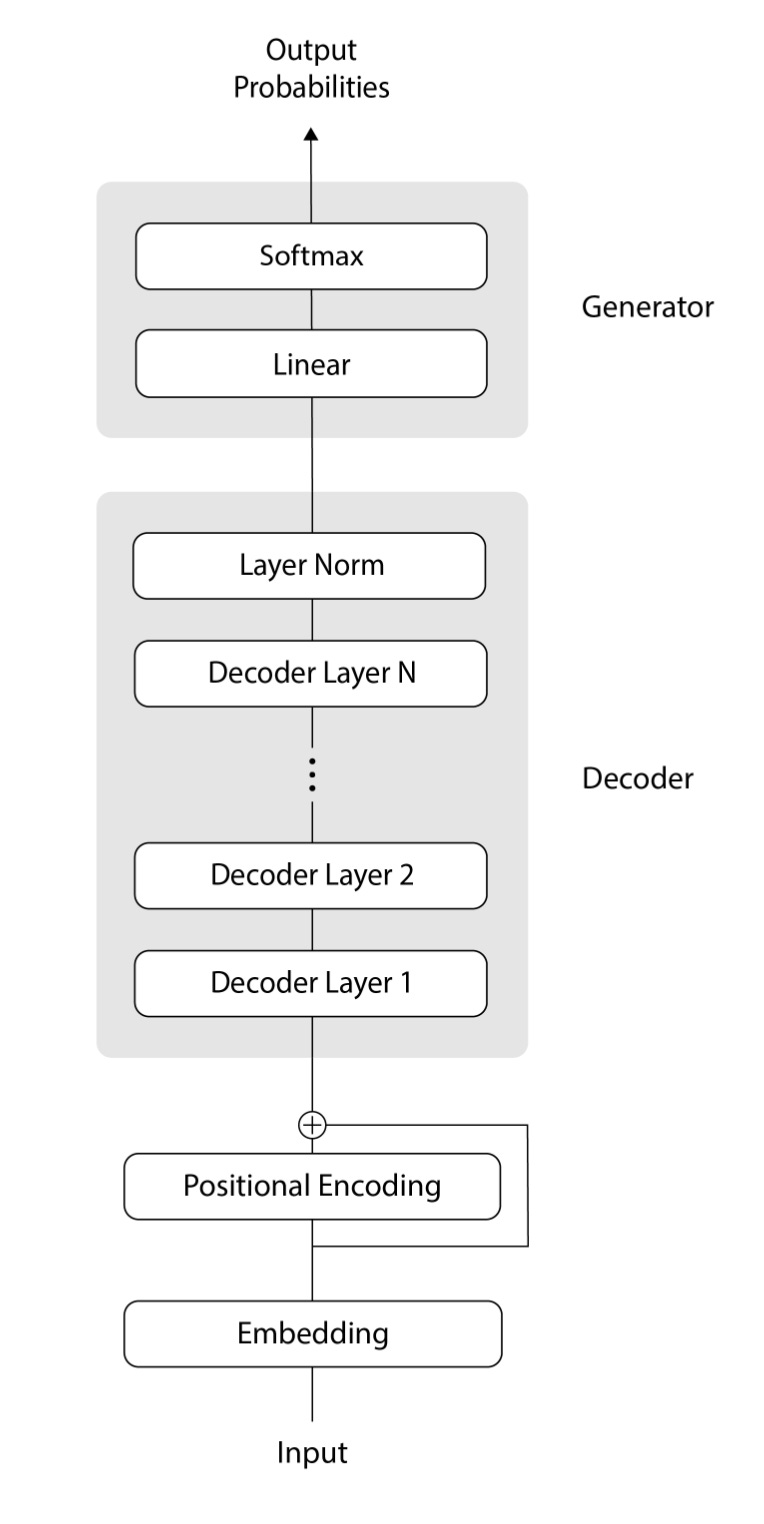
The original GPT model had the following specifications18:
12 decoder-only transformer layers
768-dimensional hidden states
12 attention heads
117 million parameters
Key Architectural Choices:
Several decisions in GPT’s architecture are crucial for its performance:
Decoder-only Architecture: GPT only uses the decoder portion of the Transformer model, which is well-suited for tasks where the goal is to generate text. The model processes inputs in sequence, predicting one word at a time based on previous words.
Masked Self-attention: In GPT, the self-attention mechanism is masked, meaning each word can only "look at" previous words in the sequence. This keeps the autoregressive nature intact, where each word is predicted based on earlier context, making the model highly effective for generating coherent text.
Layer Normalization Placement: GPT applies layer normalization before the attention and feed-forward layers (pre-norm), rather than after (post-norm), which improves stability during training, especially for deeper models.19
Scaling Up: GPT's larger size compared to previous language models is a key factor in its improved performance. Increasing the number of parameters, attention heads, and layers allows GPT to better capture complex patterns in language.
2.2.3 Mathematical Intuition Behind GPT
As discussed earlier, the GPT architecture is made of the following layers:
Multi-head self-attention - we discussed this at length with BERT.
Self Attention:
\(\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V\)The only significant difference here vs. the self-attention mechanism I described earlier is the addition of the Mask matrix (M) within the softmax function. This addition before applying the softmax function to the result of the scaled dot-product operation ensures the autoregressive nature of the Transformer decoder at the heart of GPT as it makes sure that each word only considers the words that came before it.
Multi-Head Attention: This works just as the multi-head attention mechanism for the encoder part of a Transformer (BERT) works, in that it combines the attention of each specialized head to gather a broader understanding of the context of the input sequence.
Layer Normalization:
\(\text{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta\)Where
mu (μ) and sigma (σ) are the mean and standard deviation of the inputs.
mu represents the central tendency of the data. Normalizing by subtracting the mean removes any bias in the data and centres it around 0, thus making it easy for computations.
sigma squared (σ^2) is the variance of the inputs that gives us an insight into the spread or distribution of the input data. Dividing by the standard deviation (sigma) ensures the input values are scaled to have unit (1) variance, meaning they will have a standard range and magnitude.x is the input to the layer normalization. (output from the previous layer). A good intuition here is to think of it as an activation from the previous layer for each element in the batch. It is a vector/tensor of size corresponding to the layer’s input.
ϵ is a small constant added to the denominator to prevent division by 0. This is important to maintain numerical stability - as it ensures that no matter how small the variance is, the division does not result in an undefined operation due to division by 0.
γ is a learned scale parameter that adjusts the normalized output. After normalizing the input, the network can learn to scale it up or down just by scaling γ.
β is a learned bias parameter that shifts the normalized output. After normalization, β lets the network shift normalized values to better align with the most optimal data distribution for the task at hand instead of being centred around a mean of 0.
The way Layer Normalization works is as follows:
Center the input by subtracting the mean
Scale the centred input by dividing by the standard deviation to achieve unit variance
Rescale the normalized input using a learnable scaling factor
Shift the normalized input using a learnable bias.
This sequence ensures that the input data is properly scaled and centred for the next layer in the network, making learning more stable and efficient.
Feed-Forward Neural Network:
\(\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\)This is a simple two-layer neural network applied to each word after the self-attention and normalization process. This step helps refine the representation of each word, making the model’s understanding of the data more detailed.
Layer Normalization: This is the same process as what happens before the neural network layer.
These operations work together to allow GPT to process input sequences and generate coherent and contextually relevant text. The self-attention mechanism enables the model to consider the entire context when predicting each token, while the feed-forward networks and layer normalization help in processing and stabilizing this information.
An important part of this model is its autoregressive nature which is implemented through masked self-attention - which teaches the model to generate one word at a time. This is key to its ability to generate text. The way this works is that it allows the model to predict the next token based only on the words that came before it, rather than looking at the entire sentence at once. This autoregression is similar to how we humans also generate language for writing and speaking and is a key factor in GPT’s ability to produce coherent and contextually appropriate text.20
This architecture, combined with training on a large corpus of diverse text, is the secret behind GPT’s ability to capture complex language patterns and generate human-like text across a wide range of tasks and domains.
2.2.4 Evolution of the GPT Models:
Since its initial release in 2018, the GPT (Generative Pre-trained Transformer) family has undergone significant transformations, with each new version introducing innovations that enhance its capabilities and address previous limitations. What began as a groundbreaking model for natural language generation has evolved into a versatile family of models capable of tackling an increasingly wide range of tasks. In this section, we’ll explore the major milestones in GPT’s evolution and how each iteration has pushed the boundaries of what language models can achieve.
GPT-1 (2018)
The original GPT model, introduced by OpenAI in 2018, established the basic architecture21:
117 million parameters
12-layer decoder-only transformer
Used byte pair encoding (BPE) for tokenization
Trained on BookCorpus (7,000 unpublished books)
Demonstrated the effectiveness of unsupervised pre-training followed by supervised fine-tuning
Architectural features:
First to use transformer decoder for language modeling
Introduced layer normalization before each sub-block
Used learned position embeddings instead of sinusoidal
GPT-2 (2019)
GPT-2 represented a major leap in scale and capability22:
Largest variant had 1.5 billion parameters (10x increase from GPT-1)
Trained on WebText, a more diverse dataset (45 million links from Reddit)
Introduced zero-shot task transfer
Architectural changes:
Layer normalization was moved to the input of each sub-block
Increased context size from 512 to 1024 tokens
Added an additional layer normalization after the final self-attention block
Modified initialization scaling
GPT-3 (2020)
GPT-3 marked another order-of-magnitude increase in scale23:
175 billion parameters
Trained on a much larger and more diverse dataset, including Common Crawl
Demonstrated impressive few-shot learning abilities
Architectural changes:
Alternating dense and locally banded sparse attention patterns in the layers
Used a version of byte-level BPE tokenization
Further increased context size to 2048 tokens
Adjusted hyperparameters for stable training at scale
GPT-4 (2023)
The latest iteration, GPT-4, brings further advancements24:
Multimodal capabilities, accepting both image and text inputs
Significantly improved performance across a wide range of tasks
Architectural changes:
Full details of GPT-4's architecture have not been disclosed
Introduced a novel system for multimodal inputs
Likely incorporates advanced techniques for improving factual accuracy and reasoning capabilities
Each iteration of GPT has not only increased in size but also refined its architecture to improve performance, efficiency, and generalization capabilities. The evolution from GPT-1 to GPT-4 represents a shift from models that required task-specific fine-tuning to more general-purpose AI systems capable of adapting to a wide variety of tasks with minimal additional training.
The architectural changes across versions have focused on improving the model's ability to handle longer contexts, process information more efficiently, and capture more complex patterns in the data. These refinements, combined with increases in model size and training data, have led to the impressive capabilities we see in the latest GPT models.
3.0 Current State of the Art
Over the last four years, the landscape of Large Language Models (LLMs) has rapidly evolved. While the GPT family of models remains widely recognized, especially due to the success of ChatGPT, new models such as Google’s PaLM and Gemini, Meta’s open-source LLaMA series, the open-source Mistral, and Anthropic’s Claude have introduced innovative improvements in performance, efficiency, and specialized applications. Let’s explore what makes these models unique and what key innovations set them apart.
PaLM (Pathways Language Model), developed by Google, is a landmark in model design thanks to its Pathways architecture. The Pathways architecture is what truly sets PaLM apart from its predecessors. Pathways allows the model to activate only the relevant parts of the network for specific tasks, reducing the computational overhead by avoiding the need to activate the entire model for every task. This enables efficient scaling of model parameters, making it highly effective for a variety of tasks while optimizing computational resources.
This architecture also ensures PaLM performs exceptionally well on a range of natural language processing tasks, including advanced reasoning, math problems, and even code generation. By selectively routing tasks through specialized parts of the network, Pathways allows the model to be flexible and task-efficient, pushing the limits of performance while keeping costs under control.
Meta’s LLaMA (Large Language Model Meta AI) models, particularly in the latest version LLaMA 3.1, range up to 405 billion parameters, far surpassing earlier versions. The success of LLaMA models can be attributed to the Chinchilla scaling laws, which propose that smaller models trained on larger datasets outperform much larger models trained on less data. This principle allows LLaMA models to efficiently leverage computational resources while achieving high performance across various tasks.
Even though LLaMA has grown significantly in size, with its largest variant now at 405B parameters, it continues to offer superior performance compared to earlier models like GPT-3, thanks to the balance between model size and the volume of training data. This makes LLaMA a powerful and efficient tool for researchers and developers.
Mistral has quickly become a pioneer in model efficiency, setting new benchmarks despite its smaller size of only 7 billion parameters. The key to its success lies in its use of Grouped-Query Attention (GQA) and Sliding Window Attention (SWA).
Grouped-query attention (GQA) optimizes memory usage by grouping queries, reducing the attention overhead without sacrificing accuracy. This innovation allows Mistral to handle long sequences more efficiently, enabling better performance in real-time applications.
Sliding Window Attention (SWA) is another powerful technique used by Mistral to process long inputs. Instead of processing the entire input at once, SWA allows the model to focus on smaller, relevant chunks of the input. This reduces the computational complexity for longer sequences, making Mistral highly efficient when handling documents or other long-form text data.
With these attention mechanisms, Mistral can achieve performance levels on par with much larger models, offering a balance of speed, memory efficiency, and accuracy.
Claude developed by Anthropic, Claude is unique among modern models due to its focus on safety, ethics, and responsible AI. Claude’s architecture is designed to minimize harmful outputs, making it well-suited for use in sensitive applications such as moderation, customer service, and AI-driven ethical decision-making.
Claude’s standout feature is its rigorous safety-focused architecture, which has been fine-tuned to avoid producing biased or harmful outputs. While it might not be as widely benchmarked as other models like PaLM or LLaMA, Claude’s role in socially impactful applications makes it particularly important in fields where transparency, ethics, and fairness are paramount.
Gemini, another groundbreaking model from Google DeepMind, takes things to the next level by integrating multimodal capabilities, meaning it can process both text and visual data simultaneously. This positions Gemini as a highly versatile model that is not only capable of understanding natural language but can also interpret and interact with images.
By combining these two modalities, Gemini opens up a new realm of possibilities in applications such as image captioning, visual question answering, and even robotics control. Leveraging DeepMind’s expertise in reinforcement learning and multimodal reasoning, Gemini is set to push the limits of what language models can achieve beyond text-based tasks, entering fields that involve complex, real-world data.
As we've explored, the latest generation of large language models represents the forefront of artificial intelligence, with innovations that have transformed how we approach natural language processing, text generation, and even multimodal understanding. These models have introduced new methods for improving efficiency, handling larger datasets, and adapting to more complex tasks across various domains.
However, as advanced as these models are, they are not without limitations. Despite their breakthroughs, certain challenges remain—some tied to their computational demands, others to issues like accuracy and ethical considerations. Addressing these limitations is essential for the continued evolution of AI technologies and ensuring they can meet the diverse needs of real-world applications.
In the following section, we will delve into the key shortcomings of these models, examining the obstacles that still stand in the way of their full potential.
4.0 LLMs and Inference
So far, I have talked a lot about training language models, their varied architectures and the various innovations in this field over the years. However, there is a very important part of the story here that remains to be talked about - Inference. This is perhaps the single most important aspect of LLMs to most readers. The reason is that this is what drives how you interact with a model.
Inference is the phase where a model generates outputs based on a given input. Unlike in the training phase, where models learn from data, inference is about applying this learned knowledge to generate text - answer questions, perform tasks, etc.
The world of inference is just as vast and varied as the world of training a model. Let’s dive into what this entails and how different optimizations make it possible for us to interact with these models.
4.1 The Inference Process:
At its foundation, the inference process can be summarized in the following two phases:
4.1.1 Prefill Phase
The prefill phase processes the entire input prompt to establish the initial context. It involves:
Input Processing: The input prompt X = (x_1, x_2, ..., x_n) is tokenized and converted into embeddings: E = (e_1, e_2, ..., e_n) where
\(e_i = \text{Embed}(x_i)\)Forward Pass: The model processes all tokens in parallel, computing hidden states for each layer
\(l: H^l = \text{TransformerLayer}_l(H^{l-1})\)Where H^0 = E, and TransformerLayer_l includes self-attention and feed-forward operations:
\(\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 \)Final Layer Computation: The final layer produces logits for the entire vocabulary:
\(Z = H^L W_\text{out} + b_\text{out}\)Where L is the total number of layers, and
\(W_\text{out}, b_\text{out} \)are the output layer parameters.
4.1.2 Decode Phase
The decode phase generates new tokens one at a time. For each new token:
Token Selection: Compute probabilities for the next token using softmax:
\(P(x_{n+1}|x_1, ..., x_n) = \text{softmax}(z_{n+1})\)Where z_(n+1) is the logit vector for the next token.
Sampling: Select the next token using a sampling strategy (e.g., top-k, nucleus sampling).
Incremental Forward Pass: Update the hidden states for the new token:
\(h^l_{n+1} = \text{TransformerLayer}_l([h^{l-1}_1, ..., h^{l-1}n, h^{l-1}{n+1}])\)Note that this operation only needs to compute the new token's hidden state, leveraging the cached states from previous tokens.
Iteration: Repeat steps 1-3 until a stop condition is met.
4.1.3 How are these different?
Computational Complexity:
Prefill: For sequence length n and model dimension d:
\( O(n^2d) \)Decode (per token): As it only processes one new token against the existing sequence, its complexity is:
\(O(nd)\)
Memory Usage:
Prefill: Requires storing all intermediate activations, O(nLd) for L layers.
Decode: Uses KV-cache to store keys and values, reducing memory access but increasing storage to O(nLd).
Parallelism:
Prefill: Highly parallelizable, processing all input tokens simultaneously.
Decode: Limited parallelism, processing one token at a time.
Understanding these phases is crucial for optimizing LLM inference. The prefill phase, while more computationally intensive, occurs only once per prompt. The decode phase, less compute-intensive but repeated for each generated token, often becomes the bottleneck in interactive applications. This two-phase approach allows for efficient processing of both the initial context and subsequent token generation, balancing comprehensive context understanding with rapid token generation.
4.2 Challenges with Current State of the Art LLMS
As Large Language Models have scaled in size and complexity, they have truly transformed the field of Natural Language Processing, enabling more powerful and versatile applications. However, alongside these advancements come significant challenges that need to be addressed to ensure their efficient and reliable deployment. These challenges not only affect the quality and accuracy of the models’ outputs but also impact their scalability, computational requirements, and real-world applicability. So, let’s talk about some of these challenges faced by LLMs today:
4.2.1 Computational Intensity and Latency
The massive size of modern LLMs often results in high computational demands, making both training and inference resource-intensive. Running models like GPT-4 or PaLM at scale requires large amounts of processing power, memory, and energy. These models frequently rely on clusters of GPUs or TPUs, which limits accessibility for smaller organizations or individual users.
Impact: This computational burden translates into longer inference times and higher costs, which can be prohibitive for real-time or cost-sensitive applications like customer service, healthcare, and personalized recommendations.
4.2.2 Scalability and Deployment Challenges
The larger and more complex the model, the more difficult it becomes to scale and deploy in production environments. As LLMs grow in size, the infrastructure needed to support them—both in terms of hardware and software—becomes increasingly specialized. This complexity introduces bottlenecks in deploying these models efficiently across a range of environments, from cloud platforms to edge devices.
Impact: Many organizations struggle to integrate LLMs into their workflows due to the hardware requirements and latency issues associated with serving such large models. This limits the real-world applicability of LLMs, especially in scenarios requiring rapid responses, such as autonomous systems or interactive chatbots.
4.2.3 Energy Consumption and Environmental Concerns
One of the often-overlooked challenges of modern LLMs is their energy consumption. The large-scale training and inference processes consume vast amounts of electricity, contributing to higher operational costs and raising concerns about the environmental impact of running such models. For instance, training models like GPT-3 or LLaMA can emit as much carbon as a vehicle driving several hundred thousand miles.
Impact: The energy-intensive nature of LLMs has raised ethical questions about the sustainability of scaling up AI models. As we look to develop even larger models, the industry must consider how to balance innovation with environmental responsibility.
4.2.4 Hallucinations and Output Reliability
Hallucinations are one of the most fundamental problems that persist through generations of LLMs, where LLMs generate plausible-sounding but factually incorrect information. Despite advancements in language understanding and generation, models often produce outputs that are not grounded in reality, particularly when asked about specific or niche topics. This can be especially problematic in critical applications such as healthcare, legal advice, or customer support.
Impact: The tendency of models to hallucinate raises concerns about their reliability, especially when the generated information is used in decision-making processes. Users must often manually verify model outputs, which diminishes the efficiency of AI-based solutions in high-stakes environments.
4.2.5 Bias and Ethical Considerations
LLMs, like all machine learning models, are trained on vast datasets that reflect the biases present in human-generated content. These inherent biases can lead to outputs that are discriminatory, harmful, or otherwise ethically problematic. While there has been significant work to mitigate these issues, bias in LLM outputs remains an ongoing concern.
Impact: The presence of bias in LLMs poses risks when deploying these models in sensitive areas such as hiring, legal judgments, and content moderation. If not adequately addressed, biased outputs can perpetuate inequalities and harm vulnerable communities.
4.2.6 Interpretability and Explainability
LLMs operate as black boxes, meaning it’s often difficult to understand how a model arrived at a particular conclusion or generated a specific output. This lack of interpretability makes it challenging to trust the decisions made by these models, particularly in domains where transparency is essential.
Impact: The black-box nature of LLMs limits their use in regulated industries such as healthcare, finance, and law, where explainability is crucial for compliance and accountability. Without interpretability, it becomes harder to debug or improve model behaviour when things go wrong.
4.3 Optimizing Inference in Large Language Models
Now we know that inference is the phase which defines the user experience. Given the sheer scale and complexity of these models, optimizing the inference process is essential for efficient, real-world deployment. Without these optimizations, inference can be computationally expensive and slow, particularly when working with longer input sequences or datasets (Try feeding Claude or ChatGPT a long text or PDF and ask them questions and you’ll know exactly what I’m talking about).
Therefore, in this section, I will explore some key optimization techniques that enhance the efficiency of inherence among these models. Each of these techniques significantly reduce the computational load of LLMs and enable faster and more scalable outputs.
4.3.1 Caching - Reusing Intermediate Computations
Caching is a technique that reduces the need for repetitive calculations by storing intermediate results, such as hidden states and attention weights, during inference. This cached data can be reused to generate subsequent tokens without recalculating everything from scratch.
How Caching Works:
During text generation, the model processes each token sequentially. Instead of recomputing the hidden states for every new token, caching stores these states, allowing the model to retrieve and use them directly. This reduces the overall number of forward passes required.
Mathematical Explanation:
Let’s assume that at time step t, the model computes hidden state H_t. To generate the next token, the model uses H_t as part of the input to compute H_(t+1) in the following manner:
Here, by caching H_t, the model avoids recomputing it in future steps, reducing computational redundancy and speeding up the inference process.
4.3.2 Batching: Parallelizing Inference for Efficiency
Batching is an effective way to parallelize inference across multiple input sequences. By processing batches of inputs simultaneously, batching leverages the parallel processing capabilities of modern GPUs and TPUs to handle larger workloads and reduce latency.
Mathematical Explanation:
For a batch of input sequences represented by X, the hidden states for all sequences in the batch are computed as:
Where X is the batch of input embeddings, W is the weight matrix, and H_batch represents the hidden states for all input sequences in the batch.
Batching is particularly useful in large-scale production environments, where high throughput is necessary. Studies have demonstrated its efficiency in handling simultaneous requests during inference, reducing computational bottlenecks.
4.3.3 Quantization: Reducing Precision for Speed and Memory Efficiency
Quantization converts high-precision model parameters into lower-precision formats (e.g., from 32-bit floats to 16-bit floats or 8-bit integers), significantly reducing memory usage and speeding up inference. While quantization may slightly degrade model accuracy, the trade-off is often minimal, particularly for real-time applications requiring high throughput.
Mathematical Explanation:
Quantization transforms weights from floating-point precision to a lower-precision integer format:
Where:
x_f is the original floating-point value,
x_q is the quantized value,
x_min and x_max are the minimum and maximum values of the parameter range,
n is the number of bits (e.g., 8-bit quantization).
Recent works on Mistral 7B and Llamma models by open-source contributors (Llama.cpp project) have shown that quantization can significantly improve memory efficiency and inference speed while decreasing computational requirements, making it more feasible to deploy large models on less powerful computers.
4.3.4 Advanced Attention Mechanisms: Efficient Long-Sequence Processing
Long input sequences pose a challenge for LLMs due to the quadratic scaling of standard attention mechanisms. Grouped-query attention (GQA) and Sliding Window Attention (SWA) are two advanced methods designed to handle long sequences more efficiently by reducing the attention computation required.
Grouped-Query Attention (GQA) groups multiple queries, allowing attention operations to be shared across them, reducing memory and computational overhead.
Sliding Window Attention (SWA) limits the scope of attention to a fixed window of tokens, improving the efficiency of processing long sequences by focusing attention only on the most relevant tokens.
Mathematical Explanation (Self-Attention):
Self-attention computes attention weights as:
Where:
Q, K, and V are the query, key, and value matrices derived from input tokens,
d_k is the dimensionality of the key vectors.
Grouped-Query attention (GQA) modifies this by processing grouped queries together, which reduces the overall number of attention operations. Sliding Window Attention (SWA) focuses attention on a fixed window of tokens, improving the efficiency of processing long sequences.
5.0 Applications of Large Language Models
Large Language Models (LLMs) have found their way into a myriad of applications, revolutionizing how we interact with and leverage artificial intelligence. Their ability to understand and generate human-like text has opened up new possibilities across various domains:
5.1 Natural Language Processing Tasks
LLMs excel in traditional NLP tasks such as:
Text Classification: Categorizing documents, sentiment analysis, and topic modelling.
Named Entity Recognition: Identifying and classifying named entities in text.
Machine Translation: Translating text between languages with high accuracy.
Summarization: Generating concise summaries of longer texts.
Question Answering: Providing accurate answers to questions based on given context.
5.2 Content Generation
LLMs have shown remarkable capabilities in generating various types of content:
Creative Writing: Producing stories, poems, and scripts.
Technical Writing: Generating reports, documentation, and academic papers.
Code Generation: Writing and completing code snippets across programming languages.
Ad Copy and Marketing Material: Creating engaging marketing content.
5.3 Conversational AI
LLMs power advanced conversational AI systems:
Chatbots: Engaging in human-like conversations for customer service and support.
Virtual Assistants: Performing tasks and answering queries in natural language.
Therapy Bots: Providing mental health support through conversation.
5.4 Information Retrieval and Analysis
LLMs enhance information retrieval systems:
Semantic Search: Understanding the context and intent behind search queries.
Data Analysis: Extracting insights from unstructured text data.
Research Assistance: Aiding researchers in literature review and hypothesis generation.
6.0 Future Innovations in LLM Technology
As LLM technology continues to evolve, several promising directions are emerging that aim to address current limitations and expand the capabilities of these models:
6.1 Retrieval Augmented Generation (RAG)
RAG is a technique that combines the generative capabilities of LLMs with the ability to retrieve and incorporate external information:
Concept: RAG models augment the generation process by first retrieving relevant information from a large corpus and then conditioning the language model on this retrieved context.
Mathematical Formulation: Let (x) be the input query, (z) the retrieved information and (y) the generated output. RAG models optimize:
\([ p(y|x) = \sum_{z} p(z|x) p(y|x,z) ]\)Where (p(z|x)) is the retrieval model and (p(y|x,z)) is the generator.
Advantages:
Improves factual accuracy by grounding generations in external knowledge.
Allows for real-time updates to the knowledge base without retraining the entire model.
Enhances transparency by providing sources for generated information.
6.2 Mixture of Experts (MoE)
MoE is an architecture that aims to increase model capacity without a proportional increase in computation:
Concept: Instead of a single large model, MoE uses multiple "expert" networks, each specializing in different aspects of the task.
Mathematical Formulation: Given input (x), the output (y) is computed as:
\([ y = \sum_{i=1}^N g_i(x) \cdot f_i(x) ]\)Where (g_i(x)) is the gating function determining the contribution of the expert (f_i(x)).
Advantages:
Scales model capacity with only a marginal increase in computational cost.
Allows for task-specific specialization within a single model.
Potentially improves performance on diverse tasks.
6.3 Mixture of Agents (MoA)
MoA is an emerging paradigm that combines multiple AI agents to solve complex tasks:
Concept: Multiple specialized AI agents collaborate to solve problems, each bringing unique capabilities to the task.
Key Components:
Task Decomposition: Breaking complex problems into subtasks.
Agent Selection: Choosing the right agent for each subtask.
Coordination: Managing the flow of information between agents.
Integration: Combining outputs from multiple agents into a coherent solution.
Advantages:
Leverages specialized capabilities of different models or systems.
Improves problem-solving abilities on complex, multi-faceted tasks.
Enhances adaptability to new or changing task requirements.
7.0 Conclusion
Since the beginning of the era of computing, the field of Language Modelling has seen remarkable progress, transforming from simple statistical models to sophisticated neural architectures capable of understanding and generating human-like text. From the foundational work on neural networks to the breakthrough of the Transformer architecture, and the subsequent scaling of models like GPT, BERT, and their successors, we've witnessed a paradigm shift in natural language processing.
These advancements have not been without challenges. The increasing size of models has necessitated innovations in training techniques, hardware utilization, and inference optimization. Innovations like model parallelism, efficient attention mechanisms, and specialized hardware have been crucial in making these large models practical.
As we look to the future, innovations like Retrieval Augmented Generation, Mixture of Experts, and Mixture of Agents promise to address current limitations and open new possibilities. These techniques aim to enhance the accuracy, efficiency, and applicability of LLMs, potentially leading to more robust and versatile AI systems.
However, as these models become more powerful and pervasive, it's crucial to address ethical considerations, including bias, fairness, and the societal implications of AI-generated content. The responsible development and deployment of LLMs will be as important as their technical capabilities.
In conclusion, the field of Large Language Models stands at an exciting juncture. With their ability to understand and generate human-like text, these models are not just tools for natural language processing tasks but are increasingly becoming general-purpose problem-solving systems. As research continues to push the boundaries of what's possible, we can anticipate LLMs playing an even more significant role in shaping the future of artificial intelligence and its applications in our daily lives.
Today, I leave you with a lot to digest - a lot of math and a lot of exciting new information about the marvel that is the Large Language Model. In the end, I just hope I have done justice to the truly fascinating history and science behind these magical tools that have become such a big part of our everyday lives. I hope you enjoyed reading this as much as I enjoyed writing it and I hope you take away something of value from this as always. I will be back next week talking about another interesting topic as part of this series on Language Modeling.
If you enjoyed reading this, please leave a like, and share this post with your friends at the click of a button below.
Thank you for reading.
~ Pritish
"Model Training," C3 AI Glossary, accessed September 14, 2024, https://c3.ai/glossary/data-science/model-training/.
"Training ML Models," Amazon Machine Learning Developer Guide, accessed September 14, 2024, https://docs.aws.amazon.com/machine-learning/latest/dg/training-ml-models.html.
"Machine Learning Models," Databricks Glossary, accessed September 14, 2024, https://www.databricks.com/glossary/machine-learning-models.
"What is the Size of the Training Set for GPT-3?" OpenAI Developer Forum, accessed September 14, 2024, https://community.openai.com/t/what-is-the-size-of-the-training-set-for-gpt-3/360896.
Ashish Vaswani et al., “Attention Is All You Need,” arXiv.org, August 2, 2023, https://arxiv.org/abs/1706.03762v7.
Jacob Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, May 24, 2019, https://arxiv.org/pdf/1810.04805.pdf.
Yonghui Wu et al., "Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation," arXiv, October 8, 2016, https://arxiv.org/pdf/1609.08144.
Diederik P. Kingma and Jimmy Lei Ba, "Adam: A Method for Stochastic Optimization," presented at the International Conference on Learning Representations (ICLR), 2015, https://arxiv.org/pdf/1412.6980.
Rishi Bommasani et al., "On the Opportunities and Risks of Foundation Models," arXiv, August 16, 2021, https://arxiv.org/pdf/2108.07258.
Jacob Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, May 24, 2019, https://arxiv.org/pdf/1810.04805.pdf.
Ibid
Ibid
Ashish Vaswani et al., “Attention Is All You Need,” arXiv.org, August 2, 2023, https://arxiv.org/abs/1706.03762v7.
Niklas Heidloff, "Foundation Models: Transformers, BERT, and GPT," Niklas Heidloff Blog, accessed September 14, 2024, https://heidloff.net/article/foundation-models-transformers-bert-and-gpt/.
Tom B. Brown et al., "Language Models are Few-Shot Learners," arXiv, May 28, 2020, https://arxiv.org/pdf/2005.14165.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever, "Improving Language Understanding by Generative Pre-Training," OpenAI, 2018, https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
Beatrix Stollnitz, "Understanding GPT and the Transformer Model," Bea Stollnitz Blog, accessed September 14, 2024, https://bea.stollnitz.com/blog/gpt-transformer/.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever, "Improving Language Understanding by Generative Pre-Training," OpenAI, 2018, https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
Alec Radford et al., "Language Models are Unsupervised Multitask Learners," (2019), https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
Tom B. Brown et al., "Language Models are Few-Shot Learners," in Advances in Neural Information Processing Systems33, ed. H. Larochelle et al. (Curran Associates, Inc., 2020), 1877-1901, https://arxiv.org/pdf/2005.14165.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever, "Improving Language Understanding by Generative Pre-Training," OpenAI, 2018, https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
Alec Radford et al., "Language Models are Unsupervised Multitask Learners," (2019), https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
Tom B. Brown et al., "Language Models are Few-Shot Learners," in Advances in Neural Information Processing Systems33, ed. H. Larochelle et al. (Curran Associates, Inc., 2020), 1877-1901, https://arxiv.org/pdf/2005.14165.
OpenAI, "GPT-4 Technical Report," arXiv preprint arXiv:2303.08774 (2023), https://arxiv.org/pdf/2303.08774.