
Retrieval-Augmented Generation: Enhancing Large Language Models with Dynamic Knowledge Integration
Integrating dynamic knowledge with LLMs

Large Language Models have revolutionized workflows across industries and have changed the nature of knowledge work and perhaps the process of knowledge and information transfer as it existed over the millennia. However, they face several significant challenges which limit their real-world applicability and reliability when it comes to things that actually matter. Today, I will dive into some of these challenges in-depth and explore an innovative approach to trying to improve LLM performance called Retrieval Augmented Generation (RAG) as a promising solution.
1.0 Challenges with Large Language Models
Last week, I talked at length about the various approaches to Large Language Models and how their different architecture and design choices affect how they interact with their end-users. Today, as we discuss using these models, it is important to understand the various challenges faced by these models in everyday tasks.
1.1 Limited Context Windows
Any LLM model has a hard upper limit to how much text they can process at once. This is called the context window of an LLM and it stems from the models’ architecture and training processes. The context window is the maximum number of tokens that an LLM can consider at any given time when generating or processing language. Now, the key idea here is that LLMs are trained to predict the next successive element in a sequence. Where do tokens fit in here? Tokenization is the process of breaking up a sequence into multiple discrete, atomic elements called tokens. These tokens then go on to form the model’s vocabulary or the corpus of elements that the model is trained to recognize, process, and predict. Depending on the tokenization technique used, a token can be a word, part of a word, a vector, or some entirely different form of representation. Usually, in the context of Language Models, context windows range from around 2048 tokens in the earlier GPT models to 128,000 tokens in the GPT-4o model.
Context windows are important because they allow these models to use a sliding mechanism to “slide” the context window over the input sequence while discarding older parts of the sequence to make room for the newer parts of the input sequence. Within each successive context window, these models then apply attention to weigh the importance of the different parts of the sequence to understand the sequence. However, this comes with a trade-off. Larger context windows allow increased comprehension but also increase the computational and memory resources required for efficient model inference.
Functionally, this context window, determined during pre-training of the model, is tied to the model’s architecture, particularly in its attention layers. Therefore, changing a model’s context window would require fundamental changes in the model architecture and design.
As a result of this, having a limited size window really imposes tradeoffs and limits on the model’s abilities.
1.2 Static Knowledge Cutoff
Another significant limitation of Large Language Models is their static knowledge cutoff. This means that the information they possess is only up-to-date until the point when their training data was last updated. For instance, if an LLM was trained on data available up to the year 2021, it would have no awareness of events, discoveries, or developments that occurred after that time.
This static nature arises because LLMs are trained on vast datasets collected at a specific time. Once the training is complete, the model doesn't automatically update itself with new information. Any new data that emerges post-training isn't incorporated unless the model undergoes a new training phase or fine-tuning, which, as we've discussed, is computationally intensive and not always practical.
In practical terms, this limitation means that when you ask an LLM about recent events—like the latest news, technological advancements, or current market trends—it may not provide accurate or relevant information. This can be particularly challenging in fields that require the most current data, such as finance, healthcare, or technology sectors.
1.3 Hallucinations and Factual Inconsistencies
One of the more perplexing challenges with LLMs is their tendency to "hallucinate" or produce information that is incorrect or entirely fabricated, yet presented confidently as factual. This happens because LLMs generate responses based on patterns in the data they were trained on, without an inherent understanding of truth or falsehood.
But what are hallucinations?
Hallucinations occur when the model produces output that seems plausible but isn't grounded in its training data or reality. For example, an LLM might generate a convincing-sounding historical "fact" that never actually happened or cite a scientific "study" that doesn't exist.
Apart from hallucinations, LLMs can also exhibit factual inconsistencies within the same response or across different interactions. This inconsistency arises because the model doesn't have a mechanism to verify the accuracy of the information it generates; it relies solely on the probability of word sequences.
1.4 Computational Inefficiency in Fine-Tuning
Fine-tuning is the process of taking a pre-trained LLM and adjusting it to perform better on a specific task or within a particular domain. While fine-tuning can enhance the model's performance, it comes with significant computational costs.
Why Is Fine-Tuning Computationally Intensive?
Large Parameter Sizes: LLMs often have billions of parameters. Adjusting these parameters requires substantial computational resources.
Extended Training Times: Fine-tuning can take hours to days of processing time on high-end hardware.
Resource Accessibility: Not all organizations or individuals have access to the necessary computational infrastructure, such as powerful GPUs or TPUs.
This comes with a trade-off because while fine-tuning can make models more accurate for specific tasks, the resources required can be a barrier to implementation. This inefficiency limits the adaptability of LLMs in dynamic environments where quick adjustments are necessary.
1.5 Difficulty in Adapting to New Information
Building on the issue of static knowledge, LLMs also struggle with incorporating new information on the fly. Since they don't have a built-in mechanism to update their knowledge base dynamically, adapting to new data requires retraining or fine-tuning.
Challenges in Adaptation
Latency: The time it takes to retrain or fine-tune a model means there's a delay before new information is incorporated.
Cost: Frequent retraining is not cost-effective due to computational expenses.
Practicality: In fast-moving fields, by the time a model is updated, the information might already be outdated.
Impact on Real-world Applications
In scenarios like emergency response, stock market analysis, or social media monitoring, the inability to process and integrate new information promptly can significantly reduce the effectiveness of LLMs.
2.0 Moving Ahead - How do we solve these challenges
Understanding these challenges is the first step toward overcoming them. The limitations of traditional LLMs highlight the need for models that are more adaptable, efficient, and accurate. This brings us to the exploration of innovative strategies aimed at enhancing LLM capabilities.
2.1 Overview of Improvement Strategies
Researchers and practitioners have been actively seeking solutions to address the shortcomings of LLMs. Some of the prominent strategies include:
Retrieval-Augmented Generation (RAG): Integrating external knowledge bases with LLMs to provide up-to-date and contextually relevant information.
Fine-tuning with Domain-Specific Data: Adjusting models to perform better in specific areas by training them on specialized datasets.
Prompt Engineering: Crafting inputs in a way that guides the model to produce more accurate and relevant outputs.
Few-Shot Learning: Enabling models to learn new tasks with a minimal amount of new data.
2.2 The Need for Dynamic Knowledge Integration
At the core of many LLM challenges is the need for models to access and integrate new information dynamically. A model that can incorporate real-time data without the need for retraining would be a significant advancement.
Benefits of Dynamic Integration
Up-to-date Responses: Models can provide information that reflects the most recent data and events.
Resource Efficiency: Reduces the need for frequent retraining, saving computational resources.
Improved Reliability: Enhances trust in AI systems by minimizing inaccuracies and outdated information.
2.3 Balancing Accuracy, Efficiency, and Adaptability
The quest for enhanced LLMs involves finding the right balance among several factors:
Accuracy: Ensuring the information provided is correct and reliable.
Efficiency: Making the best use of computational resources to reduce costs and processing times.
Adaptability: Allowing models to adjust to new information and different contexts seamlessly.
Achieving this balance is challenging but essential for the development of AI systems that are both powerful and practical for real-world applications.
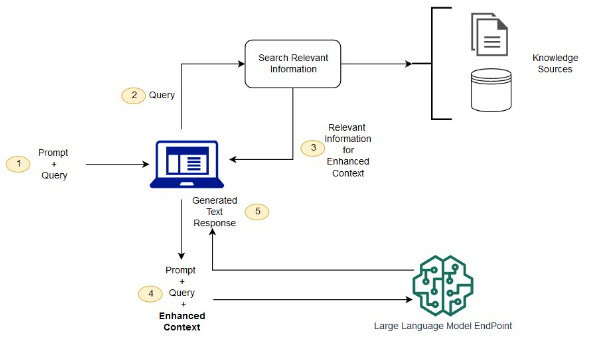
3.0 Enter Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) is an innovative approach that synergizes the strengths of retrieval-based methods and generative models in natural language processing. By integrating external knowledge sources during the generation process, RAG aims to enhance the accuracy, factuality, and relevance of the generated text.1 At its core, RAG consists of two primary components: a retriever and a generator.
3.1 Retriever Component
The retriever in RAG is responsible for accessing and retrieving relevant information from a vast corpus of documents. It leverages Dense Passage Retrieval (DPR), which is a state-of-the-art retrieval system designed for open-domain question answering.^[2]
The DPR framework comprises:
Query Encoder: A BERT-based model that encodes input queries into dense vector representations in a continuous vector space. This encoder captures the semantic meaning of queries beyond mere keyword matching.
Document Encoder: Another BERT-based model that encodes documents (or passages) into the same vector space as the queries. This ensures that semantically similar queries and documents are close in the vector space.
Document Index: A collection of pre-computed document embeddings stored in an efficient nearest neighbour search index, such as FAISS (Facebook AI Similarity Search).^[3] FAISS enables rapid similarity searches over large datasets by optimizing for efficient storage and retrieval.
The retrieval process can be mathematically represented as follows:
Where:
x is the input query.
z represents a document from the corpus.
Embed_input(x) is the query embedding.
Embed_doc(z) is the document embedding.
f(x,z) is the relevance score computed as the dot product of the query and document embeddings.
p_η(z∣x) denotes the probability of selecting document z given query x, parameterized by η.
3.2 Generator Component
The generator in RAG is typically a pre-trained sequence-to-sequence (seq2seq) model, such as BART (Bidirectional and Auto-Regressive Transformers).^[4] The generator takes both the original input query and the retrieved documents as context to generate the final output, effectively grounding its responses in external knowledge.
RAG proposes two main variants:
RAG-Sequence: Uses the same retrieved document(s) for generating the entire output sequence. The generator conditions on the query and a fixed set of retrieved documents throughout the generation process.
RAG-Token: Allows for different retrieved documents to influence each generated token. This means that at each time step during generation, the model considers multiple documents, enabling finer-grained integration of retrieved information.
For RAG-Sequence, the generation probability is defined as:
For RAG-Token, the probability is defined as:
Where:
y is the output sequence.
y_i is the i-th token in the output sequence.
θ represents the parameters of the generator model.
p_θ (y∣x,z) is the probability of generating y given query x and retrieved document z.
top-k(pη(⋅∣x)) denotes the set of top k documents retrieved based on the probability p_η (z∣x).
These equations capture how the generator combines information from multiple retrieved documents to produce a coherent and informed response.
3.3 Training and Inference
RAG models are trained end-to-end, treating the retrieved documents as latent variables. The training objective is to maximize the marginal likelihood of the correct output over all possible retrieved documents.2
Training Objective
The training objective can be expressed as:
Where:
L is the loss function.
y_j is the target output for the j-th training example.
x_j is the input query for the j-th training example.
p(y_j∣x_j) is the marginal likelihood of the correct output given the input query, computed by summing over all possible retrieved documents.
Marginalization Over Latent Documents
During training, the model marginalizes over the latent documents z:
Inference Process:
During inference, RAG uses a top-k approximation to marginalize over the latent documents, considering only the most relevant retrieved documents to make the computation tractable. This allows the model to incorporate multiple pieces of relevant information when generating outputs.
4.0 Performance and Usability Implications of RAG
4.1 Improved Accuracy and Factuality
RAG models have demonstrated significant improvements in accuracy and factuality across various natural language processing tasks:
Open-Domain Question Answering: RAG models have achieved state-of-the-art results on benchmarks such as Natural Questions, TriviaQA, and WebQuestions, outperforming both parametric-only models and previous retrieval-augmented methods.3
Fact Verification: On the FEVER dataset, which focuses on verifying factual claims against evidence, RAG approaches the performance of complex pipeline systems without requiring intermediate retrieval supervision.4
Abstractive Question Answering: On tasks like MS MARCO, which require generating detailed answers, RAG outperforms strong baselines by producing more factual and specific responses.5
4.2 Enhanced Specificity and Diversity
Human evaluations have indicated that RAG-generated text is often more specific and diverse compared to traditional language models:
Jeopardy Question Generation: In experiments, RAG outputs were judged to be more factual in 42.7% of cases, compared to only 7.1% for a BART baseline without retrieval augmentation.6
Diversity Metrics: RAG models produce a higher ratio of distinct n-grams in generated text, indicating more varied and less repetitive outputs without the need for specialized decoding strategies.
4.3 Computational Considerations
While RAG models offer enhanced performance, they introduce additional computational considerations:
Retrieval Latency: The retrieval step adds latency to the generation process. However, this can be mitigated through efficient indexing and approximate nearest neighbour search techniques, such as Maximum Inner Product Search (MIPS) provided by FAISS.7
Memory Requirements: Storing a large document index can be memory-intensive, especially when dealing with extensive knowledge bases containing millions of documents.^[1] Strategies such as index compression and hierarchical storage can help alleviate memory constraints.
4.4 Interpretability and Knowledge Updating
RAG offers notable advantages in terms of interpretability and ease of updating knowledge:
Provenance of Information: The retrieved documents serve as evidence for the generated responses, providing transparency and making it easier to verify the sources of information.
Dynamic Knowledge Updates: Since the document index is separate from the model parameters, updating the knowledge base with new information is straightforward and does not require retraining the entire model. This allows the system to stay current with the latest information.
5. Future Innovations in RAG
As RAG continues to evolve, several promising directions for future research and innovation have emerged.
5.1 Improved Retrieval Mechanisms
Learned Retrieval: Developing more sophisticated retrieval mechanisms that can better understand the context and intent of queries. This includes incorporating techniques from models like REALM (Retrieval-Augmented Language Model Pre-training), which integrates retrieval into the pre-training process.8
Multi-Modal Retrieval: Extending RAG to retrieve and incorporate information from diverse data types, such as images, videos, and structured data, enabling the model to handle multi-modal queries and responses.
5.2 Enhanced Integration of Retrieved Information
Adaptive Fusion Techniques: Creating advanced methods for integrating retrieved information with the generator's parametric knowledge. This could involve dynamic weighting of retrieved documents based on their relevance and reliability.
Multi-Hop Reasoning: Enabling RAG models to perform multi-step reasoning by iteratively retrieving and synthesizing information across multiple documents. This approach is akin to how humans gather and connect information from different sources to form a comprehensive understanding.
5.3 Efficiency and Scalability
Retrieval Efficiency: Developing techniques to reduce retrieval latency, such as hybrid sparse-dense retrieval methods or learned index structures. Building on MIPS techniques used in DPR and REALM, these methods aim to optimize retrieval speed without sacrificing accuracy.910
Model Compression: Exploring ways to compress RAG models while maintaining performance, making them more suitable for deployment in resource-constrained environments, such as mobile devices or edge computing platforms.
5.4 Ethical Considerations and Bias Mitigation
Bias in Retrieved Information: Addressing potential biases present in the document corpus. Developing methods to detect and mitigate the impact of biased or harmful content on generated outputs is crucial for responsible AI deployment.
Transparency and Explainability: Enhancing the interpretability of RAG models, especially in high-stakes applications like healthcare or legal domains. By providing clear explanations and sources, RAG can build user trust and facilitate better decision-making.
5.5 Domain Adaptation and Few-Shot Learning
Task-Specific Retrieval: Developing techniques to quickly adapt RAG models to new domains or tasks with minimal fine-tuning. Incorporating ideas from REALM's pre-training approach can help models generalize better to unseen data.11
Few-Shot RAG: Exploring how RAG can enhance few-shot learning capabilities by leveraging the retrieval mechanism to find relevant examples or information, thereby reducing the amount of labelled data required for new tasks.
6. Conclusion
Retrieval-Augmented Generation (RAG) represents a significant advancement in the field of natural language processing, offering a powerful framework that combines the strengths of large language models with the ability to access and leverage external knowledge [Lewis et al., 2020]. As we've explored, RAG models have demonstrated superior performance across a range of knowledge-intensive tasks, from open-domain question answering to fact verification and abstractive summarization.
Looking ahead, the evolution of RAG points towards even more sophisticated architectures that blur the lines between retrieval-augmented models, Mixture-of-Experts systems, and intelligent agents. Future innovations may see RAG models developing specialized retrievers for different domains, much like a mixture of experts approach, where each expert retriever is dynamically selected based on the input query. Furthermore, by integrating retrieval into broader cognitive architectures, we may see the emergence of more agent-like systems that can plan, make decisions, and use tools based on retrieved information.
These advancements promise to address current limitations in AI systems, such as the need for more flexible and adaptable knowledge access, improved reasoning capabilities, and better handling of multi-modal information. At the same time, they raise important questions about ethical AI development, bias mitigation, and explainability that will need to be addressed as these systems become more complex and powerful.
In conclusion, while RAG has already made significant contributions to NLP, its true potential may lie in paving the way for the next generation of AI systems that can seamlessly combine retrieval, expertise, and agency. As research in this area continues to evolve, we can expect to see transformative applications across a wide range of domains, fundamentally changing how AI systems understand, reason about, and interact with the world.
Lewis, P., Perez, E., Piktus, A., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS). Retrieved from https://arxiv.org/abs/2005.11401
Ibid
Ibid
Ibid
Ibid
Ibid
Johnson, J., Douze, M., & Jégou, H. (2017). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data. Retrieved from https://arxiv.org/abs/1702.08734.
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). REALM: Retrieval-Augmented Language Model Pre-Training. Proceedings of the 37th International Conference on Machine Learning (ICML). Retrieved from https://arxiv.org/abs/2002.08909.
Karpukhin, V., Oguz, B., Min, S., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Retrieved from https://arxiv.org/abs/2004.04906.
Lewis, M., Liu, Y., Goyal, N., et al. (2019). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Retrieved from https://arxiv.org/abs/1910.13461
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). REALM: Retrieval-Augmented Language Model Pre-Training. Proceedings of the 37th International Conference on Machine Learning (ICML). Retrieved from https://arxiv.org/abs/2002.08909.